

单目 SLAM 简介:您是否想过特斯拉的自动驾驶汽车如何观察周围环境、了解其位置,并做出智能决策以到达目标位置?

好吧,它使用的方法叫做SLAM。先冷静一下!在你兴奋之前,这并不是关于机器人参加摔跤比赛或将某人摔倒在地的事情。
同步定位与地图构建(简称SLAM )是机器人技术和 3D 计算机视觉领域的一个著名术语。它是机器人感知技术不可或缺的一部分,负责使机器人能够在未知地形中导航。同步定位与地图构建(简称 SLAM)是一种在未知环境中定位机器人的方法。
这是我们机器人文章系列的第二部分。在上一篇博文中,我们深入概述了自主机器人的四个组成部分。在本文中,我们将仅关注感知模块,特别是定位。我们将逐步介绍单目视觉 SLAM,并用 Python 实现一个简单的版本。我们将分解所有数学部分,使其更容易理解。稍后,我们将简要讨论ORB-SLAM及其运行方法。有关完整概述,请查看目录。
如果您是机器人领域的新手,我们建议您阅读我们之前的文章《机器人技术简介》。文章讨论了机器人技术的最新发展、机器人自动化的核心组件、工业和学术界使用的机器人工具以及就业机会。
我们希望现在这篇博文的目的已经很明确了,所以让我们开始行动吧!
💡 您只需订阅博客即可访问此博客文章的整个代码库,我们会向您发送代码链接。

什么是 SLAM?
SLAM 的直觉可以用这个类比来描述,
想象一下,在一个完全黑暗的房间里,你只能用手电筒一次看清一小片区域。要导航,你必须同时根据照明区域确定你当前的位置(定位),并通过记住你在移动过程中遇到的物体的位置和特征来创建房间的地图(制图)。

一般来说,解决 Localization 问题有两种方法,
- 先建图再定位:创建环境地图(建图),然后使用该地图估计机器人的位置(姿势)。在预建地图上进行定位比 SLAM 效率高得多。
- SLAM:在机器人移动时,同时创建地图并估计机器人在地图中的位置。SLAM 的计算量比先绘制地图再定位要大。
从鲁棒解决方案的角度来看,SLAM 听起来更有效,因为每次面对未知环境时创建新地图是低效的。
注意:
- 姿势确切地意味着 6 个自由度 (DoF) [x, y, z, r, p, y],这里 x,y,z 是笛卡尔坐标,r, p, y 是 3D 空间中的欧拉角。
- 我们交替使用了术语“相机姿势”和“机器人姿势”;两者都表示机器人在 3D 坐标系中的位置。
什么是视觉SLAM?
当我们使用相机作为 SLAM 算法的输入时,它被称为视觉 SLAM。如果使用单个相机,它被称为单目视觉 SLAM。当涉及两个或一组相机时,它被称为立体视觉 SLAM。
让我们简要介绍一下立体和单目视觉 SLAM 的一些主要优点和缺点。请注意,这篇文章目前将集中讨论单目,但我们可能会在本系列的后续文章中记录和发布有关立体 SLAM 实现的内容。
| 方面 | 立体 SLAM | 单视觉 SLAM |
| 轨迹估计 | 优点:可以估算出以米为单位的精确轨迹 | 缺点:估计轨迹的唯一性取决于比例因子 |
| 鲁棒性 | 优点:由于数据更多,通常更加稳健 | 缺点:由于数据点较少,稳定性可能较差 |
| 计算复杂性 | 缺点:计算要求更高 | 优点:计算要求较低 |
| 3D 映射功能 | 缺点:需要两个摄像头并进行校准 | 优点:只需要一个摄像头,设置更简单 |
| 3D 重建细节 | 优点:生成精确且密集的 3D 地图 | 缺点:生成的 3D 地图不太准确且比较稀疏 |
| 环境适应性 | 优点:更善于捕捉精细细节和深度信息 | 缺点:细节和深度准确度较差 |
| 设置复杂性 | 缺点:可能会受到相机之间光线差异的影响 | 优点:单摄像头设置下性能稳定 |
什么是单目SLAM?
问题表述
我们已经直观地了解了单目视觉 SLAM。现在让我们了解它在数学上是如何表述的。
输入:
给定随时间变化的环境摄像机帧序列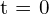 , 到
, 到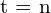 ,表示为,
,表示为,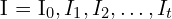
输出:
查找,摄像机(机器人)的轨迹.webp) , 这里,
, 这里,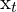 是相机的姿势。
是相机的姿势。
以及环境地图.webp) ,pt代表三维坐标。
,pt代表三维坐标。
客观的:
给定视觉观察,最大化轨迹 X 和映射 M 的概率(后验概率)。后验概率被描述为给定观察数据时事件发生的概率。听起来很熟悉?这是贝叶斯定理的左边。
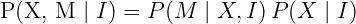
单目视觉SLAM分为更小的问题,Mapping(建图)和Odometry(里程计)。
这里,
- 映射或
.webp) :这是地图的概率(后验)
:这是地图的概率(后验)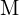 ,给定轨迹
,给定轨迹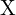 和相机框架
和相机框架.webp) 。
。 - 里程计或
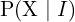 :这是相机(机器人)轨迹的概率(后验),给定视觉数据。
:这是相机(机器人)轨迹的概率(后验),给定视觉数据。
单目视觉SLAM算法概述:单目SLAM如何工作?
让我们了解单目 SLAM 的工作原理。首先,单目视觉 SLAM 所涉及的算法可以分为两大类算法:前端算法和后端算法。
- 前端算法:负责估计相机姿态和3D地图点的算法。
- 后端算法:负责优化估计的相机姿势和映射的算法。

首先,相机拍摄两张图像,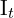 和
和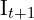 。然后对这些图像进行去畸变。之后,应用以下前端算法来估计相机姿势和 3D 地图,然后我们使用后端算法来优化先前估计的姿势和地图点。让我们了解它是如何完成的,
。然后对这些图像进行去畸变。之后,应用以下前端算法来估计相机姿势和 3D 地图,然后我们使用后端算法来优化先前估计的姿势和地图点。让我们了解它是如何完成的,
前端算法:
- 特征提取:图像之后和拍摄后,我们对两幅图像进行特征提取。比如说,
.webp) 和
和.webp) 是从图像中提取的特征和分别。
是从图像中提取的特征和分别。 - 特征匹配:接下来,我们找到提取的特征点之间的特征对应关系和.此特征匹配也可以通过跟踪图像中的特征来完成到。
- 姿势估计:通过对极几何,使用跟踪或匹配的特征点计算帧之间的相对相机姿势。对极几何从以下位置获取相应点:,以及相机固有矩阵。
- 三角测量:利用相对相机姿势和相应点,我们执行三角测量来估计周围环境的 3D 坐标。
- 局部地图构建:随着摄像机的移动,估算出的 3D 点会随时间累积,从而变成摄像机移动位置周围的局部地图。
现在,初始相机姿态和3D 地图点估计已经完成,我们使用后端算法对其进行优化。
后端算法:
- 捆绑调整:捆绑调整通过最小化所有观测的重新投影误差来细化相机姿势和 3D 点。
- 回环检测:有时相机会两次访问同一位置。在这种情况下,我们使用词袋或位置识别技术等方法识别之前访问过的位置。回环检测信息随后发送到姿势图优化。
- 姿势图优化:当检测到循环时,我们使用姿势图优化来调整整个轨迹和地图,这有助于保持全局一致性。

如果您不理解上述所有步骤,请不要担心。后面的文本将以简单易懂的语言详细解释每个要点。
前端算法
特征提取
特征是图像信息的数字化表达,一组好的特征对于最终完成指定任务的效果至关重要,因此多年来研究人员对特征的提取进行了广泛的研究。
经典计算机视觉中的这些特征与深度学习特征不同。在经典计算机视觉中,这些特征是手工制作的并表示为特征点,特征点是图像中的一些特殊位置。以图 1 为例,我们可以看到角落、边缘和块是图像中的代表性位置。

一个特征点由两部分组成:关键点和描述子。
- 关键点:关键点是指特征点在图像上的 2D 位置。某些类型的关键点还包含其他信息,例如方向和大小。
- 描述子:描述子通常是一个向量,描述关键点周围像素的信息。描述子的设计应该使得外观相似的特征具有相似的描述子。因此,如果两个特征描述子在向量空间中很接近,则可以将它们视为同一特征。

SIFT(尺度不变特征变换)是众所周知的经典特征提取算法之一,以其准确性和鲁棒性而闻名。与此相反,SIFT 的计算量很大,这使得它的计算量很大。另一方面,ORB(定向 FAST 和旋转 BRIEF)特征被广泛用于实时特征提取。它使用FAST(定向 FAST)的修改版本和极快的二进制描述符BRIEF,大大加快了整个图像特征提取过程。
代码:
下面是使用 ORB 进行特征提取的 OpenCV python代码。
1 2 3 4 5 | # Initialize the ORB detector with 5k keypointsorb = cv2.ORB_create(nfeatures=5000)# Detect keypoints and compute descriptorskeypoints, descriptors = orb.detectAndCompute(image, None) |

ORB特征提取说明:
ORB 特征提取的主要思想是,如果一个像素与相邻像素差异很大(太亮或太暗),则它很可能是一个角点。其整个过程如下,
- 选择像素
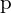 假设图像的亮度为
假设图像的亮度为.webp) 。
。 - 设定阈值
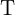 (例如,20%)。
(例如,20%)。 - 取像素作为中心,选择半径为3的圆上的16个像素。
- 如果有连续
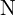 所选圆上亮度大于
所选圆上亮度大于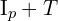 或小于
或小于.webp) ,则中心像素p可视为一个特征点。通常为 12、11 或 9。
,则中心像素p可视为一个特征点。通常为 12、11 或 9。 - 对每个像素重复上述四个步骤。

使用一个技巧来拒绝大多数非角点,首先检查位置 1、9、5 和 13 处的像素。这些像素中至少 N 个的亮度必须大于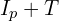 或小于
或小于.webp) 该点被视为角点。
该点被视为角点。
现在,您可能还不明白它与单目 SLAM 有何关系,但请耐心听我说完。随着您阅读这些章节,您将能够将这些点联系起来。
特征匹配
特征匹配紧随特征提取之后。特征匹配是 Visual SLAM 中的一个重要部分,用于在两个连续帧之间找到匹配的特征。
在计算机视觉术语中,这意味着在两幅图像中找到特征对应关系。比如说,你有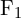 来自的特征第帧,以及
来自的特征第帧,以及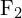 来自框架的对应特征
来自框架的对应特征 。
。
对于第 I 帧中的每个点,计算与第 I 帧中的所有点的平方差和 (SSD). 计算最佳匹配(最小距离)与次佳匹配(第二小距离)的比率。如果该比率低于阈值,则保留匹配对,否则拒绝匹配对。此过程会过滤可信特征对应关系,然后使用这些特征对应关系来估计相机在世界坐标系中的旋转和平移。

此代码初始化 ORB 检测器以查找关键点并计算两个图像的描述符,使用cv2. BFMatcher()匹配描述符,并按距离对匹配进行排序以确定最佳匹配。
代码:
1 2 3 4 5 6 7 8 9 10 11 12 十三 14 15 16 17 | # Initialize the ORB detectororb = cv2.ORB_create(nfeatures=1000)# Detect keypoints and compute descriptors for the first imagekeypoints1, descriptors1 = orb.detectAndCompute(image1, None)# Detect keypoints and compute descriptors for the second imagekeypoints2, descriptors2 = orb.detectAndCompute(image2, None)# Initialize the BFMatcher with default paramsbf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)# Match descriptors between frame I and frame I+1matches = bf.match(descriptors1, descriptors2)# Sort matches by distance (best matches first)matches = sorted(matches, key=lambda x: x.distance) |

特征跟踪可用于替代特征匹配,以完成逐帧跟踪关键点的任务。跟踪关键点具有计算效率,这对于实时应用至关重要。但是,在某些情况下跟踪可能会失败,例如大运动、误差累积引起的漂移和缺失对应关系。
下面是从第 I 帧到第 2 帧跟踪特征点的代码. 在cv2.calcOpticalFlowPyrLK函数中我们传递框架,以及来自.webp) 框架。
框架。
代码:
1 2 3 4 5 6 7 8 9 10 11 12 | # Parameters for lucas kanade optical flowlk_params = dict(winSize=(15, 15),maxLevel=2,criteria=(cv2.TERM_CRITERIA_EPS | cv2.TERM_CRITERIA_COUNT, 10, 0.03))# Calculate optical flowpoints2, status, err = cv2.calcOpticalFlowPyrLK(image1, image2, points1, None, **lk_params)# Select good pointsgood_new = points2[status.ravel() == 1]good_old = points1[status.ravel() == 1] |
姿态估计
相机姿态估计非常重要,因为只有这样做了,你才能估计 3D 地图。姿态估计是数学密集型的。要掌握这个主题,我们首先需要学习基础知识并熟悉常用术语。
首先,让我们了解世界、相机和图像坐标系,如何在二维图像中捕捉三维物体(图像形成),对极几何。

您可以单击此处体验此可视化的交互式版本。
世界坐标框架
世界坐标系 (WCF) 是计算机视觉、机器人技术和 3D 图形中使用的全局参考系,用于定义场景中物体的位置和方向。您可以将环境中的任何 3D 位置视为 WCF 的原点。例如,假设在大学校园内运行的机器人可以将大学大门视为 WCF。
相机坐标系
假设您在世界坐标系中的某个位置有一台相机。现在,如果您将相机的位置视为原点并参考任何物体相对于该相机位置的位置,则该坐标系将称为相机坐标系。
相机和世界坐标系(3D 到 3D)之间的关系,由一些表示为外部矩阵的参数定义 ![$[R \mid t]$](./slam_files/quicklatex.com-4dcc2cb5b03ce4e12a9fefc2de2fdf31_l3.png) .该矩阵有助于从世界坐标到相机坐标或反之亦然的坐标转换。
.该矩阵有助于从世界坐标到相机坐标或反之亦然的坐标转换。

图像坐标框架
图像坐标系是图像的坐标。这是二维的。一个前瞻性项目用于这种三维到二维的转换。图像坐标系可以通过固有相机参数(也称为固有矩阵(K))与相机坐标系相关联。
如果你仍然无法理解所有这些矩阵和坐标,那么就理解相机有两个矩阵:外部矩阵和内部矩阵。首先,使用外部矩阵将世界坐标系中的 3D 对象带到相机坐标系(3D 到 3D),然后使用内部矩阵将对象从相机坐标系带到图像平面/坐标系(3D 到 2D)。
后面的部分将帮助您更详细地了解这个主题。
图像形成解释

当我们捕捉图像时,物体的 3D 点会被变换并带到相机坐标系。这是一个 3D 到 3D 的变换;这是使用外部矩阵完成的。从数学上讲,它表示为:
![$\HUGE X_c = [R | t] X_w = R X_w + t$](./slam_files/quicklatex.com-42d2b410ae32c47d5da1ca14fc2cac28_l3.png)
这里,
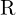 =旋转矩阵表示 3D 坐标系 (3×3) 中的旋转(或滚动、俯仰、偏航)的矩阵
=旋转矩阵表示 3D 坐标系 (3×3) 中的旋转(或滚动、俯仰、偏航)的矩阵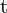 = 翻译矩阵
= 翻译矩阵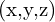 在三维坐标系中(3×1)
在三维坐标系中(3×1)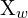 = 世界坐标系中的三维坐标
= 世界坐标系中的三维坐标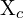 = 相机坐标系中的 3D 坐标
= 相机坐标系中的 3D 坐标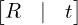 = 外部矩阵(4×4)
= 外部矩阵(4×4)
注意: 和,表示相机坐标系相对于世界坐标系的旋转和平移。
现在物体在相机坐标系中表示出来了,我们使用内在矩阵,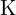 ,将三维中的物体点转换为二维中的物体点。通过这种变换,将相机坐标系中的物体投影到图像平面上。
,将三维中的物体点转换为二维中的物体点。通过这种变换,将相机坐标系中的物体投影到图像平面上。
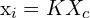
这里,
- = 内在矩阵(3×1)
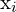 = 图像平面中的二维坐标
= 图像平面中的二维坐标- = 相机坐标系中的 3D 坐标
对极几何解释
当相机为单目时,我们只知道2D像素坐标,因此问题就是根据两组2D点来估计运动。该问题通过对极几何来解决。
您可能想知道,如果对极几何通常在立体视觉课上教授,为什么我们要在单目 SLAM 环境中讨论它?这是因为您无法仅从一张图像估计深度。要估计深度,您需要多张图像。当有多张图像时,我们使用对极几何来计算深度。在单目 SLAM 中,我们使用来自不同时间戳的图像帧来估计深度,这使得对极几何变得非常重要。

对极几何描述了同一 3D 场景的两个摄像机视图之间的关系。对极平面由两个摄像机的光学中心定义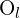 和
和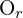 和一个 3D 点
和一个 3D 点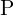 ,对极平面与图像帧的交点表示对极线
,对极平面与图像帧的交点表示对极线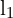 和
和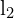 。这些线表示对应点必须位于何处,从而将匹配搜索从二维减少到一维。极点
。这些线表示对应点必须位于何处,从而将匹配搜索从二维减少到一维。极点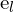 和
和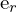 是基线(连接和)与图像平面相交。要确定帧之间的运动
是基线(连接和)与图像平面相交。要确定帧之间的运动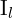 和
和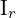 ,通过旋转定义和翻译、特征点
,通过旋转定义和翻译、特征点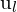 在和
在和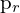 在必须正确对应,投射相同的 3D 点. 基本矩阵
在必须正确对应,投射相同的 3D 点. 基本矩阵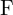 ,封装了这种关系,有助于通信和 3D 重建任务。
,封装了这种关系,有助于通信和 3D 重建任务。
在继续学习之前,让我们先了解几个来自对极几何的重要方程。要了解它们是如何推导出来的,请观看学习资料部分(底部)提到的这些视频。
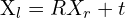 (3D 到 3D 转换)
(3D 到 3D 转换)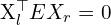 (3D 中的对极约束)
(3D 中的对极约束)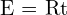 (基本矩阵)
(基本矩阵)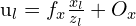 (透视投影方程)
(透视投影方程)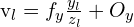 (透视投影方程)
(透视投影方程)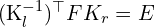 (关系和
(关系和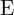 )
)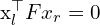 (二维中的对极约束)
(二维中的对极约束)
这里,
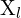 = 左相机坐标系中的点
= 左相机坐标系中的点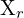 = 右相机坐标系中的点
= 右相机坐标系中的点- = 从右到左相机的旋转矩阵
- = 从右相机到左相机的平移矢量
- = 基本矩阵
- = 左摄像机图像像素空间中的 x 坐标
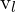 = 左摄像机图像像素空间中的 y 坐标
= 左摄像机图像像素空间中的 y 坐标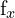 = 相机 x 方向的焦距
= 相机 x 方向的焦距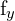 = 相机 y 方向的焦距
= 相机 y 方向的焦距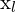 = 左图中某一点的齐次坐标
= 左图中某一点的齐次坐标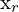 = 右图中某一点的齐次坐标
= 右图中某一点的齐次坐标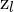 = 左相机坐标系中的深度(z 坐标)
= 左相机坐标系中的深度(z 坐标)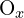 = 图像中光学中心的 x 坐标
= 图像中光学中心的 x 坐标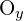 = 图像中光学中心的 y 坐标
= 图像中光学中心的 y 坐标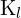 = 左摄像机的固有矩阵
= 左摄像机的固有矩阵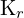 = 右相机的固有矩阵
= 右相机的固有矩阵- = 基本矩阵
给定对应关系的一小部分(仅 8 个点)(步骤 1 和 2 生成的点),我们求解,找到基础矩阵以矩阵形式来看,它看起来像这样,

这里,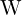 是一个× 9 矩阵源自≥ 8 个对应关系,并且 f 是我们想要的基础矩阵的值。
是一个× 9 矩阵源自≥ 8 个对应关系,并且 f 是我们想要的基础矩阵的值。
上面的方程组可以通过奇异值分解 (SVD)求解线性最小二乘来回答。找到,我们可以在第六个等式中使用它来计算之后,SVD 可用于估计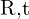 。
。
该代码从两幅图像中提取匹配的关键点,设置相机的内部参数,然后使用 RANSAC (随机样本共识)方法计算基础矩阵,以稳健地估计哪些匹配是内点。
代码:
1 2 3 4 5 6 7 8 9 10 11 12 十三 14 15 16 17 | # Extract matched keypointspts1 = np.float32([keypoints1[m.queryIdx].pt for m in matches])pts2 = np.float32([keypoints2[m.trainIdx].pt for m in matches])# Camera intrinsic parameters (example values, replace with your camera's calibration data)K = np.array([[fx, 0, cx], [0, fy, cy], [0, 0, 1]])# Compute the Fundamental matrix using RANSACF, inliers = cv2.findFundamentalMat(pts1, pts2, cv2.FM_RANSAC)# Compute the Essential matrix using the camera's intrinsic parameters E = K.T @ F @ K# Decompose the Essential matrix to get R and t_, R, t, mask = cv2.recoverPose(E, pts1_inliers, pts2_inliers, K) |
在实际场景中,特征匹配通常会包含异常值(错误对应),这是由于对应不正确、噪声或遮挡造成的。RANSAC有助于识别和排除这些异常值,以计算更准确的基本矩阵。估算基本矩阵的值后,我们可以使用 SVD 将其分解为 R 和 t,如第 3 个等式中所述 。
三角测量
上一步我们介绍了利用极线约束估计相机运动,并讨论了其局限性。估计完运动之后,下一步就是利用相机运动来估计特征点的空间位置。在单目SLAM中,单张图片无法得到像素的深度,需要通过三角测量的方法来估计地图点的深度。

三角测量是一种常用方法,用于古代确定某个点的地理位置。对极几何中使用的三角测量和地理定位的三角测量依赖于类似的概念,例如,
- 两种方法都使用三角测量原理,根据已知的参考点和测量值来确定未知位置。
- 两者都涉及几何计算,以找到空间中线或射线的交点。
对极几何中使用的三角剖分不同,它依赖于图像对应和相机校准参数。
为了估计物体的 3D 点,三角测量方法如下,
让 (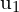 ,
,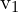 )是第一幅图像中某个点的坐标,并且(
)是第一幅图像中某个点的坐标,并且(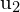 ,
,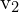 )为第二幅图像中对应点的坐标。构造投影矩阵()同时拍摄两个相机的姿势和
)为第二幅图像中对应点的坐标。构造投影矩阵()同时拍摄两个相机的姿势和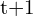 。
。
![$P1=K[I \mid 0] , P2=K[R\mid t] $](./slam_files/quicklatex.com-3be59911536a21df36c1914aafea3b88_l3.png)
3D 点之间的关系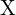 及其二维投影
及其二维投影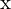 在图像中由相机投影矩阵 P 给出:
在图像中由相机投影矩阵 P 给出:
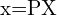
我们有两个投影矩阵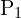 和
和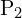 ,
, 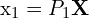 ,
,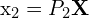 。 这里,和是
。 这里,和是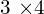 矩阵结合了相机的内在参数和外在参数。叉积
矩阵结合了相机的内在参数和外在参数。叉积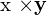 两个向量和
两个向量和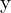 得到一个与两者正交的向量,这意味着:
得到一个与两者正交的向量,这意味着:


这些方程的出现是因为如果一个点确实位于投影线上,那么该点与其投影的叉积必定为零。展开叉积后,我们得到

这里,A 是由以下组件构成的矩阵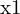 ,,
,,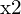 , 和。这种均匀系统的解通常使用线性最小二乘法(通常通过奇异值分解 (SVD))来找到最佳估计值。
, 和。这种均匀系统的解通常使用线性最小二乘法(通常通过奇异值分解 (SVD))来找到最佳估计值。
代码:
1 2 3 4 5 6 7 8 9 10 11 12 十三 14 15 16 17 18 19 20 21 22 23 24 二十五 二十六 二十七 二十八 二十九 三十 31 三十二 33 | import numpy as npdef add_ones(pts): """Helper function to add a column of ones to a 2D array (homogeneous coordinates).""" return np.hstack([pts, np.ones((pts.shape[0], 1))])def triangulate(pose1, pose2, pts1, pts2): # Initialize the result array to store the homogeneous coordinates of the 3D points ret = np.zeros((pts1.shape[0], 4)) # Invert the camera poses to get the projection matrices pose1 = np.linalg.inv(pose1) pose2 = np.linalg.inv(pose2) # Loop through each pair of corresponding points for i, p in enumerate(zip(add_ones(pts1), add_ones(pts2))): # Initialize the matrix A to hold the linear equations A = np.zeros((4, 4)) # Populate the matrix A with the equations derived from the projection matrices and the points A[0] = p[0][0] * pose1[2] - pose1[0] A[1] = p[0][1] * pose1[2] - pose1[1] A[2] = p[1][0] * pose2[2] - pose2[0] A[3] = p[1][1] * pose2[2] - pose2[1] # Perform SVD on A _, _, vt = np.linalg.svd(A) # The solution is the last row of V transposed (V^T), corresponding to the smallest singular value ret[i] = vt[3] # Return the 3D points in homogeneous coordinates return ret |
第 12 行和第 13 行的反转是必要的,因为给出的姿势通常是从世界坐标系到相机坐标系的转换,而我们需要逆转换才能从相机坐标系转换为世界坐标。
该代码在github 存储库中提供,您可以下载并试验。

本地映射
Visual SLAM 中的局部地图构建涉及使用从最近的观察中得出的新 3D 点更新局部地图。新三角化的点将添加到局部地图中。选择关键帧来表示重要位置。Visual SLAM 中的关键帧是指在特定时间捕获的图像以及当时对应的相机姿势(位置和方向)。关键帧和普通帧之间的区别在于,关键帧通常包含高密度的检测到的特征(关键点),用于地图构建和姿势估计。只有所有捕获的普通帧的子集被选为关键帧。
后端算法
光束法平差
捆绑调整是一个非常简单的概念,在 SLAM 和运动结构 (SfM) 社区中被广泛使用。捆绑调整是 3D 地图绘制中使用的一种过程,用于优化场景中点的位置以及拍摄这些点的相机的位置和角度。
该过程可最大限度地减少图像中点出现的位置与基于 3D 模型的点应出现的位置之间的差异。这种差异称为重新投影误差。减少此误差有助于创建精确的 3D 地图和准确的相机位置。
捆绑调整与梯度下降类似,两者都是旨在最小化误差指标的优化技术。在梯度下降中,算法迭代调整参数(例如神经网络中的权重)以减少预测值和实际值之间的差异。同样,在捆绑调整中,算法迭代细化 3D 点坐标和相机姿势以最小化重新投影误差。

代码:
1 2 3 4 5 6 7 8 9 10 11 12 十三 14 15 16 17 18 | def vertex_to_points(optimizer, first_point_id, last_point_id): """ Converts g2o point vertices to their current 3d point estimates. """ vertices_dict = optimizer.vertices() estimated_points = list() for idx in range(first_point_id, last_point_id): estimated_points.append(vertices_dict[idx].estimate()) estimated_points = np.array(estimated_points) xs, ys, zs = estimated_points.T return xs, ys, zs ipv.show()for i in range(100): optimizer.optimize(1) xs, ys, zs = vertex_to_points(optimizer, first_point_id, last_point_id) scatter_plot.x = xs scatter_plot.y = ys scatter_plot.z = zs time.sleep(0.25) |

重投影误差(RPE)可以表示为所有摄像机和点的总和
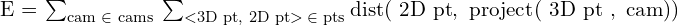
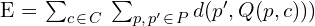
这里,
- :我们的目标是最小化总的重新投影误差。
 :所有相机 C 的集合中的一台相机。
:所有相机 C 的集合中的一台相机。- :所有 3D 点集合 P 中的一个 3D 点。
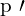 :相机c捕获的图像中观察到的对应2D点。
:相机c捕获的图像中观察到的对应2D点。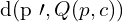 :观察到的二维点之间的距离并使用投影函数 Q 将 3D 点 p 投影到相机 c 的图像平面上。
:观察到的二维点之间的距离并使用投影函数 Q 将 3D 点 p 投影到相机 c 的图像平面上。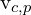 :一个二进制变量,表示 3D 点 p 是否被相机 c 观察到。如果
:一个二进制变量,表示 3D 点 p 是否被相机 c 观察到。如果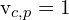 ,该点被观察到;如果
,该点被观察到;如果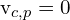 , 它不是。
, 它不是。
1 2 3 4 5 6 7 8 9 10 11 12 十三 14 15 16 17 18 19 20 21 22 23 | # Function to compute reprojection errordef compute_reprojection_error(intrinsics, extrinsics, points_3d, observations): total_error = 0 # Initialize the total error to zero num_points = 0 # Initialize the number of points to zero # Iterate through each camera's extrinsics and corresponding 2D observations for (rotation, translation), obs in zip(extrinsics, observations): # Project the 3D points to 2D using the current camera's intrinsics and extrinsics projected_points = project_points(points_3d, intrinsics, rotation, translation) # Calculate the Euclidean distance (reprojection error) between the projected points and the observed points error = np.linalg.norm(projected_points - obs, axis=1) # Accumulate the total error total_error += np.sum(error) # Accumulate the total number of points num_points += len(points_3d) # Calculate the mean reprojection error mean_error = total_error / num_points return mean_error # Return the mean reprojection error |
环路闭合检测
回环检测是后端使用的算法之一。回环检测允许系统识别机器人何时返回到之前访问过的位置,从而有效地关闭其路径中的回环。此功能对于精确的地图构建和定位至关重要,因为它有助于减少随着时间的推移而累积的漂移误差。

SLAM 系统维护一个图,其中节点表示相机姿势,边表示空间约束。当检测到回环时,会将其他边添加到图以表示新识别的连接,并应用姿势图优化或捆绑调整等优化技术来最大限度地减少总体误差。
词袋 (BoW)是一种用于 Visual SLAM 的回环检测的位置识别算法。它将图像特征转换为视觉词向量,从而创建紧凑的描述符。在回环检测期间,当前图像的 BoW 描述符会与之前访问过的位置的描述符进行比较。描述符之间的相似性表示再次访问的位置,从而使系统即使在大型环境中也能高效准确地检测回环。
DBoW2是一个开源 C++ 库,用于索引图像并将其转换为词袋表示。该库也用于 ORB-SLAM。
姿态图优化
姿势图优化是 Visual SLAM 中一个至关重要的后端步骤,用于随着时间的推移优化相机(或机器人)的估计姿势,以确保地图中的全局一致性。这种优化至关重要,因为在映射过程中,姿势估计中的小错误可能会累积,导致严重的漂移。姿势图优化通过同时优化姿势的整个轨迹来帮助纠正这些错误。
当检测到回环时,姿势图优化会整合这些约束来调整姿势并减少漂移。
姿势图优化和捆绑调整之间的区别:姿势图优化听起来可能与捆绑调整相同,但捆绑调整旨在同时细化 3D 点坐标和相机姿势。目标是最小化重新投影误差。相反,姿势图优化仅用于相机姿势细化。
Python 中的简单单目视觉 SLAM
互联网上可用的 Python 实现很少,因为它们效率低下且不实时。但从教育的角度来看,Python 实现很重要,因为它们对于任何刚开始使用 SLAM 的人来说都是一个很好的起点。

因此,我们将介绍一个仅包含 4 个文件的 Python 单目视觉 SLAM 的简单实现。此实现主要涵盖视觉 SLAM 的前端,即相机姿态估计和 3D 映射。上图 1(d) 是此 Python 实现的输出。
看起来很酷!让我们了解一下它是如何实现的。
代码结构如下,仅包含 4 个文件和一个测试视频。这不是单目视觉 SLAM 最准确的实现,但它产生了不错的结果。让我们来看看文件结构。
1 2 3 4 5 | ├── display.py├── extractor.py├── main.py├── pointmap.py└── test_countryroad.mp4 |
- extractor.py:此文件包含用于估计相机姿势的所有实用程序的代码,例如,
- 特征提取
extract - 要素匹配
match_frames - 相机姿态估计:
extractPose - 坐标规范化和反规范化
normalize:denormalize - 定义关键帧的类:
Frame
- 特征提取
- display.py:此文件包含使用名为 Simple DirectMedia Layer (SDL2) 的库进行图像可视化的代码。
- pointmap.py:此文件包含使用pangolin进行 3D 点和地图可视化的代码。
- main.py:此文件获取视频文件及其内在矩阵,并调用其他文件中的函数进行 3D 映射和相机姿势估计。
注意: 我们已经解释了代码块后的所有类和函数。但是,请同时遵循代码部分中的注释。那里的解释更清楚。
main.py说明
让我们逐一介绍它们。我们将从 开始main.py。
1 2 3 4 5 6 7 8 9 10 11 12 十三 14 15 16 17 18 19 20 21 22 23 | import cv2from display import Displayfrom extractor import Frame, denormalize, match_frames, IRt, add_onesimport numpy as npfrom pointmap import Map, Point### Camera intrinsics# define principal point offset or optical center coordinatesW, H = 1920//2, 1080//2# define focus lengthF = 270# define intrinsic matrix and inverse of thatK = np.array(([F, 0, W//2], [0,F,H//2], [0, 0, 1]))Kinv = np.linalg.inv(K)# image display initializationdisplay = Display(W, H)# initialize a mapmapp = Map()mapp.create_viewer() |
导入后,我们定义一些将在整个代码中广泛使用的非常重要的参数,其中包括,
- 光学中心坐标
- 焦距
- 内在矩阵(以及逆矩阵)
- 3D地图、图像显示初始化
1 2 3 4 5 6 7 8 9 10 11 12 十三 14 15 16 17 18 19 20 21 22 23 24 二十五 二十六 二十七 二十八 二十九 三十 31 三十二 33 三十四 三十五 三十六 三十七 三十八 三十九 40 41 四十二 43 四十四 四十五 四十六 四十七 四十八 49 50 51 52 53 54 55 56 57 58 59 60 61 | def process_frame(img): img = cv2.resize(img, (W, H)) frame = Frame(mapp, img, K) if frame.id == 0: return # previous frame f2 to the current frame f1. f1 = mapp.frames[-1] f2 = mapp.frames[-2] idx1, idx2, Rt = match_frames(f1, f2) # X_f1 = E * X_f2, f2 is in world coordinate frame, multiplying that with # Rt transforms the f2 pose wrt the f1 coordinate frame f1.pose = np.dot(Rt, f2.pose) # The output is a matrix where each row is a 3D point in homogeneous coordinates [𝑋, 𝑌, 𝑍, 𝑊] # returns an array of size (n, 4), n = feature points pts4d = triangulate(f1.pose, f2.pose, f1.pts[idx1], f2.pts[idx2]) # The homogeneous coordinates [𝑋, 𝑌, 𝑍, 𝑊] are converted to Euclidean coordinates pts4d /= pts4d[:, 3:] # Reject points without enough "Parallax" and points behind the camera # returns, A boolean array indicating which points satisfy both criteria. good_pts4d = (np.abs(pts4d[:, 3]) > 0.005) & (pts4d[:, 2] > 0) for i, p in enumerate(pts4d): # If the point is not good (i.e., good_pts4d[i] is False), # the loop skips the current iteration and moves to the next point. if not good_pts4d[i]: continue pt = Point(mapp, p) pt.add_observation(f1, i) pt.add_observation(f2, i) for pt1, pt2 in zip(f1.pts[idx1], f2.pts[idx2]): u1, v1 = denormalize(K, pt1) u2, v2 = denormalize(K, pt2) cv2.circle(img, (u1,v1), 3, (0,255,0)) cv2.line(img, (u1,v1), (u2, v2), (255,0,0)) # 2-D display display.paint(img) # 3-D display mapp.display()if __name__== "__main__": cap = cv2.VideoCapture("/path/to/car.mp4") while cap.isOpened(): ret, frame = cap.read() if ret == True: process_frame(frame) else: break |
triangulate函数已在三角测量部分讨论过。
这是工作原理process_frame:
if frame.id == 0: return非常重要,因为使用单个帧我们无法估计任何东西。- 定义当前帧和前一帧。
match_frames进行特征匹配,并在当前帧中找到对应关系。- Rt 将 f2 姿势相对于 f1 坐标系进行变换。
triangulate估计了三维地图点。- 将齐次坐标转换为欧几里得坐标,通过划分每个点W。
- 拒绝没有足够“视差”的点和相机后面的点。
- 如果该点符合上述条件,我们就将该点添加到地图中。
- 对所有好点进行非规范化处理后,绘制特征点(圆)及其跟踪轨迹(线)。
- 之后,我们通过相机姿态估计显示图像和 3D 地图。
之后,if __name__== "__main__":我们读取视频并将帧发送到“process_frame”函数。如果您有特定的视频,可以在此处输入其路径。
解释extractor.py
好奇函数是如何match_frames定义denormalize的?让我们来看看extractor.py,
1 2 3 4 5 6 7 8 9 10 11 12 十三 14 15 16 17 18 19 20 21 22 23 24 二十五 二十六 二十七 二十八 二十九 三十 31 三十二 33 三十四 三十五 三十六 三十七 三十八 三十九 40 41 四十二 43 四十四 四十五 四十六 四十七 | import cv2import numpy as npfrom skimage.measure import ransacfrom skimage.transform import FundamentalMatrixTransformimport g2odef add_ones(x): # creates homogenious coordinates given the point x return np.concatenate([x, np.ones((x.shape[0], 1))], axis=1)def extractPose(F): # Define the W matrix used for computing the rotation matrix W = np.mat([[0, -1, 0], [1, 0, 0], [0, 0, 1]]) # Perform Singular Value Decomposition (SVD) on the Fundamental matrix F U, d, Vt = np.linalg.svd(F) assert np.linalg.det(U) > 0 # Correct Vt if its determinant is negative to ensure it's a proper rotation matrix if np.linalg.det(Vt) < 0: Vt *= -1 # Compute the initial rotation matrix R using U, W, and Vt R = np.dot(np.dot(U, W), Vt) # Check the diagonal sum of R to ensure it's a proper rotation matrix # If not, recompute R using the transpose of W if np.sum(R.diagonal()) < 0: R = np.dot(np.dot(U, W.T), Vt) # Extract the translation vector t from the third column of U t = U[:, 2] # Initialize a 4x4 identity matrix to store the pose ret = np.eye(4) # Set the top-left 3x3 submatrix to the rotation matrix R ret[:3, :3] = R # Set the top-right 3x1 submatrix to the translation vector t ret[:3, 3] = t print(d) # Return the 4x4 homogeneous transformation matrix representing the pose return ret |
add_ones创建给定点的齐次坐标 。
。- 该
extractPose函数计算 表示相对于给定基本矩阵的相机姿态(旋转和平移)的齐次变换矩阵使用奇异值分解(SVD)。
表示相对于给定基本矩阵的相机姿态(旋转和平移)的齐次变换矩阵使用奇异值分解(SVD)。
1 2 3 4 5 6 7 8 9 10 11 | def extract(img): orb = cv2.ORB_create() # Detection pts = cv2.goodFeaturesToTrack(np.mean(img, axis=-1).astype(np.uint8), 1000, qualityLevel=0.01, minDistance=10) # Extraction kps = [cv2.KeyPoint(f[0][0], f[0][1], 20) for f in pts] kps, des = orb.compute(img, kps) return np.array([(kp.pt[0], kp.pt[1]) for kp in kps]), des |
- 该
extract函数使用该方法检测图像中的关键点cv2.goodFeaturesToTrack(),将其转换为 ORB 关键点,然后计算这些关键点的 ORB 描述符,返回它们的坐标和描述符。
1 2 3 4 | def normalize(Kinv, pts): # The inverse camera intrinsic matrix 𝐾^(−1) transforms 2D homogeneous points # from pixel coordinates to normalized image coordinates. return np.dot(Kinv, add_ones(pts).T).T[:, 0:2] |
- 在
normalize功能上,逆相机本征矩阵 𝐾 − 1 将 2D 齐次点从像素坐标转换为归一化图像坐标。此变换基于主点 (𝑐𝑥 , 𝑐𝑦) 将点置于中心,并根据焦距 𝑓𝑥 和 𝑓𝑦 缩放它们,从而有效地将点映射到归一化坐标系,其中主点成为原点,距离按焦距缩放。
1 2 3 4 5 6 | def denormalize(K, pt): # Converts a normalized point to pixel coordinates by applying the # intrinsic camera matrix and normalizing the result. ret = np.dot(K, [pt[0], pt[1], 1.0]) ret /= ret[2] return int(round(ret[0])), int(round(ret[1])) |
denormalize函数通过应用将规范化点转换为像素坐标。
1 2 3 4 5 6 7 8 9 10 11 12 十三 14 15 16 17 18 19 20 21 22 23 24 二十五 二十六 二十七 二十八 二十九 三十 31 三十二 33 三十四 三十五 三十六 三十七 三十八 三十九 40 41 | def match_frames(f1, f2): # The code performs k-nearest neighbors matching on feature descriptors bf = cv2.BFMatcher(cv2.NORM_HAMMING) matches = bf.knnMatch(f1.des, f2.des, k=2) # applies Lowe's ratio test to filter out good # matches based on a distance threshold. ret = [] idx1, idx2 = [], [] for m, n in matches: if m.distance < 0.75*n.distance: p1 = f1.pts[m.queryIdx] p2 = f2.pts[m.trainIdx] # Distance test # dditional distance test, ensuring that the # Euclidean distance between p1 and p2 is less than 0.1 if np.linalg.norm((p1-p2)) < 0.1: # Keep idxs idx1.append(m.queryIdx) idx2.append(m.trainIdx) ret.append((p1, p2)) pass assert len(ret) >= 8 ret = np.array(ret) idx1 = np.array(idx1) idx2 = np.array(idx2) # Fit matrix model, inliers = ransac((ret[:, 0], ret[:, 1]), FundamentalMatrixTransform, min_samples=8, residual_threshold=0.005, max_trials=200) # Ignore outliers ret = ret[inliers] Rt = extractPose(model.params) return idx1[inliers], idx2[inliers], Rt |
- 该
match_frames函数使用 BFMatcher 与 Lowe 比率测试和附加距离测试来匹配两帧之间的 ORB 描述子,使用 RANSAC 过滤内点以拟合基本矩阵,并提取相对姿势,返回内点匹配的索引和变换矩阵。
1 2 3 4 5 6 7 8 9 10 11 12 | class Frame(object): def __init__(self, mapp, img, K): self.K = K # Intrinsic camera matrix self.Kinv = np.linalg.inv(self.K) # Inverse of the intrinsic camera matrix self.pose = IRt # Initial pose of the frame (assuming IRt is predefined) self.id = len(mapp.frames) # Unique ID for the frame based on the current number of frames in the map mapp.frames.append(self) # Add this frame to the map's list of frames pts, self.des = extract(img) # Extract feature points and descriptors from the image self.pts = normalize(self.Kinv, pts) # Normalize the feature points using the inverse intrinsic matrix |
Frame该类使用内在相机矩阵、姿势以及从图像中提取的特征点和描述符初始化一个框架对象,并将该框架添加到地图对象。

解释pointmap.py
让我们了解一下如何使用pangolin来定义文件中的地图和点类pointmap.py,
1 2 3 4 5 6 7 8 9 10 11 12 十三 14 15 16 17 18 19 20 21 22 23 24 二十五 二十六 二十七 二十八 二十九 三十 31 三十二 33 三十四 三十五 三十六 三十七 三十八 三十九 40 41 四十二 43 四十四 四十五 四十六 四十七 四十八 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 | from multiprocessing import Process, Queueimport numpy as npimport pangolinimport OpenGL.GL as gl# Global map // 3D map visualization using pangolinclass Map(object): def __init__(self): self.frames = [] # camera frames [means camera pose] self.points = [] # 3D points of map self.state = None # variable to hold current state of the map and cam pose self.q = None # A queue for inter-process communication. | q for visualization process def create_viewer(self): # Parallel Execution: The main purpose of creating this process is to run # the `viewer_thread` method in parallel with the main program. # This allows the 3D viewer to update and render frames continuously # without blocking the main execution flow. self.q = Queue() # q is initialized as a Queue # initializes the Parallel process with the `viewer_thread` function # the arguments that the function takes is mentioned in the args var p = Process(target=self.viewer_thread, args=(self.q,)) # daemon true means, exit when main program stops p.daemon = True # starts the process p.start() def viewer_thread(self, q): # `viewer_thread` takes the q as input # initializes the viz window self.viewer_init(1280, 720) # An infinite loop that continually refreshes the viewer while True: self.viewer_refresh(q) def viewer_init(self, w, h): pangolin.CreateWindowAndBind('Main', w, h) # This ensures that only the nearest objects are rendered, # creating a realistic representation of the scene with # correct occlusions. gl.glEnable(gl.GL_DEPTH_TEST) # Sets up the camera with a projection matrix and a model-view matrix self.scam = pangolin.OpenGlRenderState( # `ProjectionMatrix` The parameters specify the width and height of the viewport (w, h), the focal lengths in the x and y directions (420, 420), the principal point coordinates (w//2, h//2), and the near and far clipping planes (0.2, 10000). The focal lengths determine the field of view, # the principal point indicates the center of the projection, and the clipping planes define the range of distances from the camera within which objects are rendered, with objects closer than 0.2 units or farther than 10000 units being clipped out of the scene. pangolin.ProjectionMatrix(w, h, 420, 420, w//2, h//2, 0.2, 10000), # pangolin.ModelViewLookAt(0, -10, -8, 0, 0, 0, 0, -1, 0) sets up the camera view matrix, which defines the position and orientation of the camera in the 3D scene. The first three parameters (0, -10, -8) specify the position of the camera in the world coordinates, indicating that the camera is located at coordinates (0, -10, -8). The next three parameters (0, 0, 0) # define the point in space the camera is looking at, which is the origin in this case. The last three parameters (0, -1, 0) represent the up direction vector, indicating which direction is considered 'up' for the camera, here pointing along the negative y-axis. This setup effectively positions the camera 10 units down and 8 units back from the origin, looking towards the origin with the 'up' direction being downwards in the y-axis, which is unconventional and might be used to achieve a specific orientation or perspective in the rendered scene. pangolin.ModelViewLookAt(0, -10, -8, 0, 0, 0, 0, -1, 0)) # Creates a handler for 3D interaction. self.handler = pangolin.Handler3D(self.scam) # Creates a display context. self.dcam = pangolin.CreateDisplay() # Sets the bounds of the display self.dcam.SetBounds(0.0, 1.0, 0.0, 1.0, -w/h) # assigns handler for mouse clicking and stuff, interactive self.dcam.SetHandler(self.handler) self.darr = None def viewer_refresh(self, q): # Checks if the current state is None or if the queue is not empty. if self.state is None or not q.empty(): # Gets the latest state from the queue. self.state = q.get() # Clears the color and depth buffers. gl.glClear(gl.GL_COLOR_BUFFER_BIT | gl.GL_DEPTH_BUFFER_BIT) # Sets the clear color to white. gl.glClearColor(1.0, 1.0, 1.0, 1.0) # Activates the display context with the current camera settings. self.dcam.Activate(self.scam) # camera trajectory line and color setup gl.glLineWidth(1) gl.glColor3f(0.0, 1.0, 0.0) pangolin.DrawCameras(self.state[0]) # 3d point cloud color setup gl.glPointSize(2) gl.glColor3f(1.0, 0.0, 0.0) pangolin.DrawPoints(self.state[1]) # Finishes the current frame and swaps the buffers. pangolin.FinishFrame() def display(self): if self.q is None: return poses, pts = [], [] for f in self.frames: # updating pose poses.append(f.pose) for p in self.points: # updating map points pts.append(p.pt) # updating queue self.q.put((np.array(poses), np.array(pts))) |
- 该类
Map使用 Pangolin 管理和可视化 3D 地图,其中帧表示相机姿势,点表示 3D 地图点。它运行单独的查看器线程,以持续更新和渲染 3D 场景,而不会阻塞主程序、初始化 Pangolin 窗口以及设置相机和显示上下文以进行 3D 交互。该display方法使用当前相机姿势和地图点更新队列,然后在查看器线程中渲染以可视化轨迹和 3D 点。
1 2 3 4 5 6 7 8 9 10 11 12 十三 14 15 16 17 18 | class Point(object): # A Point is a 3-D point in the world # Each point is observed in multiple frames def __init__(self, mapp, loc): self.frames = [] self.pt = loc self.idxs = [] # assigns a unique ID to the point based on the current number of points in the map. self.id = len(mapp.points) # adds the point instance to the map’s list of points. mapp.points.append(self) def add_observation(self, frame, idx): # Frame is the frame class self.frames.append(frame) self.idxs.append(idx) |
该类Point表示在多个帧中观察到的世界中的一个 3D 点。它使用位置和唯一 ID 进行初始化,将自身添加到地图的点列表中,并使用相关帧和特征索引记录观察结果。
解释display.py
最后,最后一个文件。display.py我们将要介绍的图像显示代码是使用 sdl2 编写的,
1 2 3 4 5 6 7 8 9 10 11 12 十三 14 15 16 17 18 19 20 21 22 23 24 二十五 二十六 | import sdl2import sdl2.extimport cv2class Display(object): def __init__(self, W, H): sdl2.ext.init() self.window = sdl2.ext.Window("Tim Slam", size=(W, H)) self.window.show() self.W, self.H = W, H def paint(self, img): img = cv2.resize(img, (self.W, self.H)) # Retrieves a list of SDL2 events. events = sdl2.ext.get_events() for event in events: # Checks if the event type is SDL_QUIT (window close event). if event.type == sdl2.SDL_QUIT: exit(0) # Retrieves a 3D numpy array that represents the pixel data of the window's surface. surf = sdl2.ext.pixels3d(self.window.get_surface()) # Updates the pixel data of the window's surface with the resized image. # img.swapaxes(0, 1) swaps the axes of the image array to match the expected format of the SDL surface. surf[:, :, 0:3] = img.swapaxes(0, 1) # Refreshes the window to display the updated surface. self.window.refresh() |
- 该类
Display初始化一个 SDL2 窗口以显示图像。它提供了一种paint方法来调整给定图像的大小以适合窗口,使用调整大小后的图像更新窗口的像素数据,并处理窗口事件(例如关闭)。图像的像素数据被交换以匹配 SDL 表面格式,并且窗口被刷新以显示更新后的图像。

天哪!这真是一篇很长的文章。我们希望您理解实现过程以及所有步骤如何相互关联以执行同时定位和映射。我们在本文底部添加了一些资源,其中包含 Python 中单目视觉 SLAM 的端到端实现,包括所有后端算法,例如回环、姿势图优化、捆绑调整、使用 KDTree等。
我们已经到了本文的结尾,现在是了解单目 SLAM 领域的突破之一的好时机。目前有NeRF SLAM、Gaussian Splatting SLAM等技术。但是,了解初始算法总能让你对问题有一个整体的了解,学到的工具可以在其他地方使用。
ORB-SLAM 概述
ORB-SLAM 是视觉 SLAM 领域的突破之一。ORB-SLAM 的独特之处在于它拥有构成强大 SLAM 算法的所有组件。前端和后端算法经过高效规划,专注于同时使实现更准确,使其实时。ORB-SLAM 使用 ORB 进行特征提取,但所有使用 ORB 作为特征提取的 SLAM 都不能称为 ORB-SLAM。与上述相同,SLAM 实现使用 ORB 作为其特征提取方法,但该实现不能称为 ORB-SLAM。以下是 ORB-SLAM 的贡献,

- 使用 ORB 功能执行所有任务:使用相同的 ORB 功能进行跟踪、映射、重新定位和环路闭合,确保效率、简单性和可靠性。
- 大型环境中的实时操作:使用共视性图专注于局部共视区域的跟踪和映射,与全局地图大小无关。
- 实时环路闭合:优化一个称为基本图的姿势图,该图由生成树、环路闭合链接和共视性图中的强边构建。
- 实时摄像头重定位:为视点和照明变化提供显著的不变性,允许从跟踪失败中恢复并增强地图重用。
- 稳健的初始化程序:使用模型选择自动且稳健地初始化平面和非平面场景的地图。
- 地图点和关键帧的适者生存:采用大量生成、限制性剔除的策略,通过丢弃冗余关键帧来提高追踪的稳健性并支持终身运行。
ORB-SLAM 是 SLAM 的一种创新方法。但在此之前,有多种实现也为该领域做出了类似的贡献。以下是每种实现的时间框架。

ORB-SLAM 还有另外两个后来发布的扩展,ORB-SLAM 2 和 ORB-SLAM 3。
- ORB-SLAM 2支持创建和管理多张地图,并扩展原有功能以处理RGB-D和单目摄像头,从而可以在不同环境中实现高效的建图和重定位。
- ORB-SLAM 3将惯性测量 ( IMU ) 与视觉数据相结合,以增强稳健性和准确性,并支持立体和立体惯性相机系统,在 3D 映射和定位任务中提供更多的多功能性和精度。
我们将在后续的文章中介绍 ORB-SLAM 的所有版本,并研究代码及其运行方法。
关键要点
SLAM 是将不同的方法组合在一起以创建环境的 3D 地图并估计相机姿势的集合。这就是 SLAM 如此困难的原因,因为任何事情都可能出错,而且其他部分相互依赖。因此,了解所涉及的所有步骤非常重要。
- 了解坐标系、图像形成和对极几何对于理解视觉 SLAM 算法的工作原理至关重要。
- 了解如何使用姿势估计和三角测量来估计 3D 地图点非常重要。 深入了解这些主题大有裨益,例如校准、图像拼接等。
- Python中简单单目视觉SLAM的代码讲解,特别是 main.py和extractor.py文件的代码讲解 非常重要。
结论
概率 SLAM 问题的起源发生在 1986 年旧金山举行的 IEEE 机器人与自动化会议上,标志着概率方法在机器人和人工智能领域的早期发展。快进三十多年,我们已经发展到可学习的 SLAM 和创新技术,如基于 LiDAR 的 SLAM、高斯 splatting SLAM 和 NeRF SLAM。今天,任何自主机器人,无论是波士顿动力公司的 Spot 还是特斯拉的自动驾驶汽车,都依赖 SLAM 或类似的定位技术来导航未知地形。作为一名机器人工程师,了解定位或 SLAM 的工作原理至关重要。
随着我们机器人文章系列的进展,我们将了解更高级的主题和实现,包括 ROS2、Gazebo Sim、Carla、ORB-SLAM3、LiDAR SLAM 和物体检测,最终在Carla 中构建自动驾驶汽车的最终项目。
视觉 SLAM 学习资源
用于撰写本文的论文和文章,
简单的 Python 实现,
- George Hotz 的twitchslam
- 皮斯拉姆
- 多视图笔记本
learnopencv中与相机校准和立体视觉相关的博客文章,
- 使用 OpenCV (Python/C++) 进行立体相机深度估计
- 对极几何与立体视觉简介
- 使用 OpenCV 制作低成本立体相机
- 使用 OpenCV AI Kit 实现立体视觉和深度估计
- ADAS 中的立体视觉:超越 LiDAR 的深度感知先驱
- 使用 OpenCV 进行相机校准
对极几何和深度估计视频,